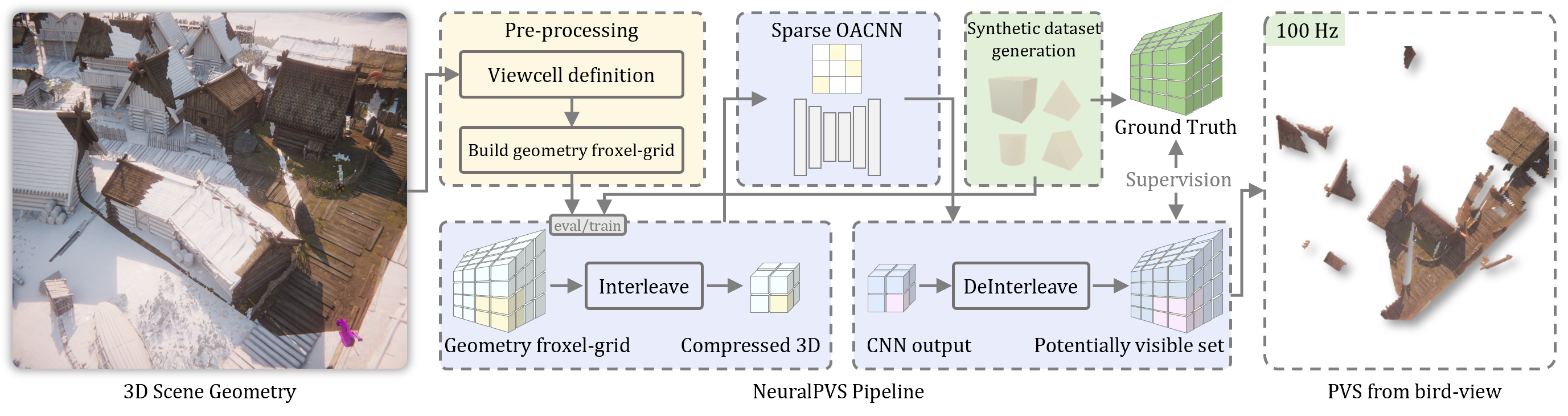
Real-time visibility determination in expansive or dynamically changing environments has long posed a significant challenge in computer graphics. Existing techniques are computationally expensive and often applied as a precomputation step on a static scene. We present NeuralPVS, the first deep-learning approach for visibility computation that efficiently determines from-region visibility in a large scene, running at approximately 100 Hz processing with less than 1% missing geometry. This approach is possible by using a neural network operating on a voxelized representation of the scene. The network's performance is achieved by combining sparse convolution with a 3D volume-preserving interleaving for data compression. Moreover, we introduce a novel repulsive visibility loss that can effectively guide the network to converge to the correct data distribution. This loss provides enhanced robustness and generalization to unseen scenes. Our results demonstrate that NeuralPVS outperforms existing methods in terms of both accuracy and efficiency, making it a promising solution for real-time visibility computation.

For each viewcell, the scene's geometry is froxelized into a GV (geometry froxel-grid), which is input to the PVS (potentially visible set) estimator network. A 3D interleaving function first compresses the GV channels; a CNN then predicts the visible part of the geometry grid; afterwards, a 3D deinterleaving function reconstructs the full PVS. Geometric primitives in froxels marked invisible in the PVS are culled from all further rendering computations.
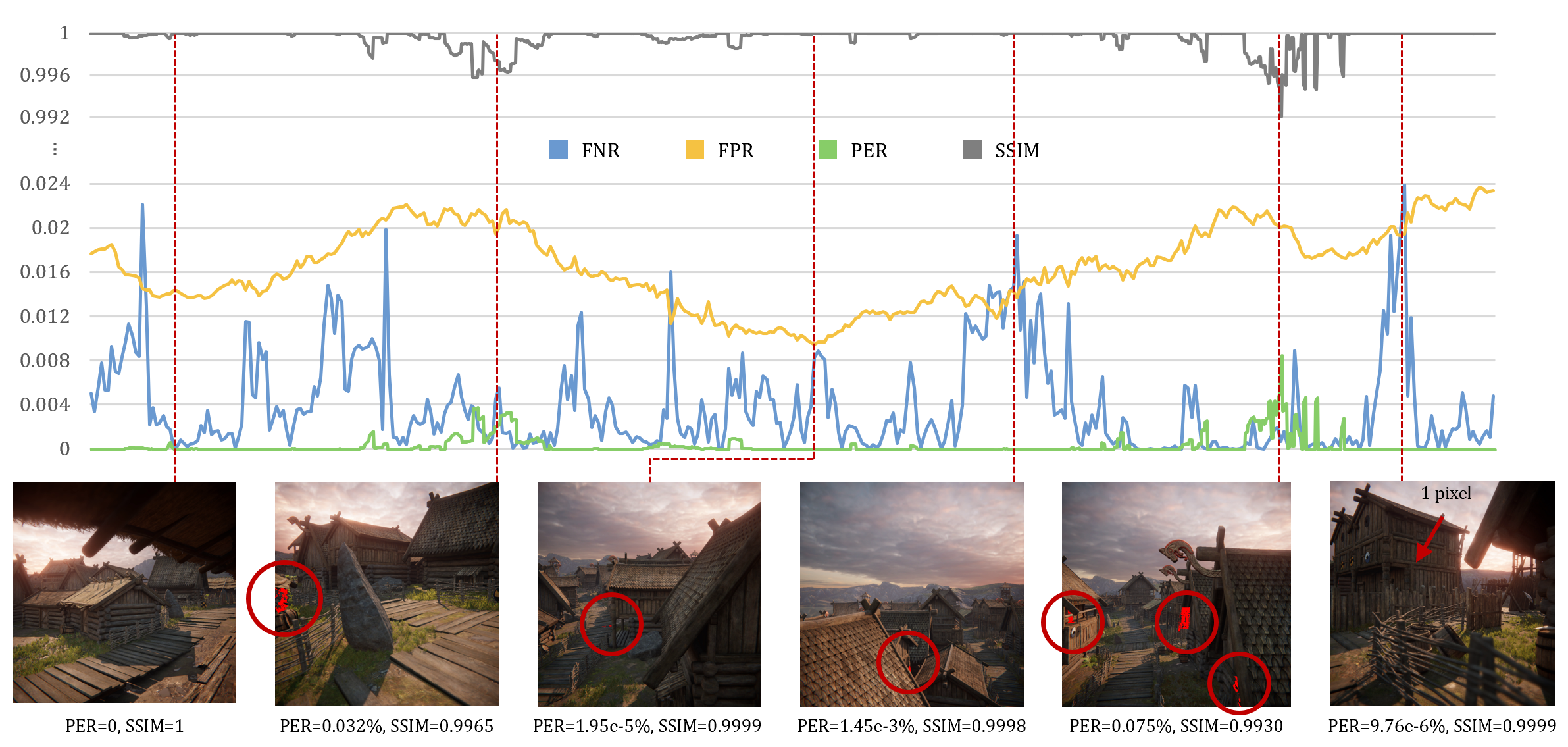
(FNR: false negative rate in froxels; FPR: false positive rate in froxels; PER: pixel error rate in the rendered image.)
Per-frame PVS estimation performance with key frames images of the Viking Village scene in the video above. The sequence has 1800 frames in total, with 410 frames of PVS computed shown in the figure. The error pixels of the key frames are marked in red on the rendered image.
For more results, please refer to the paper.
@misc{wang2025neuralpvs,
title={NeuralPVS: Learned Estimation of Potentially Visible Sets},
author={Xiangyu Wang and Thomas Köhler and Jun Lin Qiu and Shohei Mori and Markus Steinberger and Dieter Schmalstieg},
year={2025},
eprint={2509.24677},
archivePrefix={arXiv},
primaryClass={cs.GR}
}